如前所述,XmlTextReader非常类似于SAX。它们最大的一个区别是SAX是一种推模型(push model),它把数据拉入应用程序中,开发人员必须接受它,而XmlTextReader是一种拉模型,把应用程序请求的数据拉入该应用程序。这样编程就有一种更简单、更直观的模型。另一个优点是拉模型(pull model)可以选择把什么数据传送到应用程序中。如果不需要所有的数据,就不需要处理它们。而在推模型中,所有的XML数据都必须由应用程序处理,无论是否需要这些数据。
下面介绍一个非常简单的示例,读取XML数据,再详细介绍XmlTextReader类,这些代码在XmlReaderSample1文件夹中。现在用下面的代码替换前面示例中的命名空间MSXML2:
using System.Xml;
还需要从模块级代码中删除下述代码行:
private DOMDocument40 doc;
下面是按钮的单击事件处理程序:
protected void button1_Click (object sender, System.EventArgs e)
{
//Modify this path to find books.xml
string fileName = "..\\..\\..\\books.xml";
//Create the new TextReader Object
XmlTextReader tr = new XmlTextReader(fileName);
//Read in a node at a time
while(tr.Read())
{
if(tr.NodeType == XmlNodeType.Text)
listBox1.Items.Add(tr.Value);
}
}
这是XmlTextReader最简单的用法。首先,用XML文件名创建一个字符串对象,再创建一个新的XmlTextReader,其参数为fileName字符串。XmlTextReader目前有13种不同的构造函数重载版本,其参数是字符串(文件名和URL)、流和NameTables的不同组合(当元素或属性名出现几次后,它们就可以存储到NameTable中,这样比较操作的速度会较快)。
在初始化一个XmlTextReader对象后,没有选择任何节点。只有在此时,才没有当前节点。在开始tr.Read()循环后,第一个Read()会进入文档中的第一个节点,这个节点一般是XML 声明节点。在本示例,当进入每个节点时,可比较tr.NodeType 和XmlNodeType枚举,找到一个文本节点后,把该文本值添加到列表框,图23-3是加载该列表框后的屏幕图。
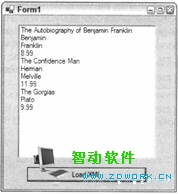
图 23-3
遍历文档有几种方式,如前面的示例所示,Read()可以进入下一个节点。然后查看该节点是否有一个值(HasValue())、该节点是否有属性(HasAttributes())。也可以使用ReadStartElement()方法,查看当前节点是否是起始元素,如果是起始元素,就可以定位到下一个节点上。如果不是起始元素,就引发一个XmlException。调用这个方法与调用Read ()后再调用IsStartElement是一样的。
ReadString() 和 ReadChars()方法都可以从元素中读取文本数据。ReadString()返回一个包含数据的字符串对象,而ReadChars()把数据读入字符数组。
ReadElementString() 类似于ReadString(),但可以把元素名作为参数。如果下一个Content节点不是起始标记,或者Name属性不匹配当前的节点Name,就会引发异常。
下面的示例说明了如何使用ReadElementString()(这段代码在XmlReaderSample2文件夹中)。注意这个示例使用FileStream,所以需要通过using语句来包括System.IO命名空间:
protected void button1_Click (object sender, System.EventArgs e)
{
//use a filestream to get the data
FileStream fs = new FileStream("..\\..\\..\\books.xml", FileMode.Open);
XmlTextReader tr = new XmlTextReader(fs);
while(!tr.EOF)
{
//if we hit an element type, try and load it in the listbox
if(tr.MoveToContent() == XmlNodeType.Element && tr.FTEL=="title")
{
listBox1.Items.Add(tr.ReadElementString());
}
else
{
//otherwise move on
tr.Read();
}
}
}
在while循环中,使用MoveToContent查找类型为XmlNodeType.Element和名称为title的节点。我们使用XmlTextReader的EOF属性作为循环条件。如果节点的类型不是Element,或者名称不是title,else子句就会调用Read()方法进入下一个节点。查找到一个满足条件的节点后,就把ReadElementString()的结果添加到列表框中。这样就在listbox中添加一个书名。注意,在成功执行了ReadElementString()后,不需要调用Read()方法,这是因为ReadElementString()已经查看了整个Element,然后定位到下一个节点上。
如果删除了if子句中的&& tr.FTEL=="title",在抛出XmlException异常时,就必须捕获它。如果查看一下数据文件,就会发现MoveToContent()查找到的第一个元素是<bookstore>,因为它是一个元素,所以把检查过程放在if语句中。但是,它不包含简单的文本类型,因此会让ReadElementString()引发一个XmlException异常。解决这个问题的一种方式是把ReadElementString()调用放在它自己的函数中。现在,如果在这个函数中ReadElementString()调用失败,就可以处理错误,返回给调用函数。
下面就调用这个新方法LoadList(),把XmltextReader作为参数。进行了这些修改后,该示例如下所示(这段代码在XmlReaderSample3文件夹中):
protected void button1_Click (object sender, System.EventArgs e)
{
//use a filestream to get the data
FileStream fs = new FileStream("..\\..\\..\\books.xml", FileMode.Open);
XmlTextReader tr = new XmlTextReader(fs);
while(!tr.EOF)
{
//if we hit an element type, try and load it in the listbox
if(tr.MoveToContent() == XmlNodeType.Element)
{
LoadList(tr);
}
else
{
//otherwise move on
tr.Read();
}
}
}
private void LoadList(XmlReader reader)
{
try
{
listBox1.Items.Add(reader.ReadElementString());
}
// if an XmlException is raised, ignore it.
catch(XmlException er){}
}
运行这段代码,结果应与前面示例的结果是一样的。因此,完成这个任务有多种不同的方式。这体现了System.Xml命名空间中类的灵活性。
在运行示例代码时,注意在读取节点时,没有看到属性。这是因为属性不是文档结构的一部分。针对元素节点,可以检查属性是否存在,并可检索属性值。
例如,如果有属性,HasAttributes就返回true,否则就返回false。AttributeCount属性确定属性的个数。GetAttribute方法按照名称或索引来获取属性。如果要一次迭代一个属性,就可以使用MoveToFirstAttribute() 和MoveToNextAttribute()方法。
下面的示例迭代XmlReaderSample4中的属性:
protected void button1_Click (object sender, System.EventArgs e)
{
//set this path to match your data path structure
string fileName = "..\\..\\..\\books.xml";
//Create the new TextReader Object
XmlTextReader tr = new XmlTextReader(fileName);
//Read in node at a time
while(tr.Read())
{
//check to see if it's a NodeType element
if(tr.NodeType == XmlNodeType.Element)
{
//if it's an element, then let's look at the attributes.
for(int i = 0; i < tr.AttributeCount; i++) {
listBox1.Items.Add(tr.GetAttribute(i));
}
}
}
这次查找元素节点。找到一个节点后,就迭代其所有的属性,使用GetAttribute()方法把属性值加载到列表框中。在本例中,这些属性是genre、publicationdate和ISBN。
