.NET 中的文档对象模型(Document Object Model,DOM)支持W3C DOM Level 1 和 Core DOM Level 2规范。DOM是通过XmlNode类来实现的。XmlNode是一个抽象类,它表示XML文档的一个节点。
还有一个XmlNodeList类,它是一个节点的有序列表。这是一个活动的节点列表,对节点的任何修改都会立即反映到列表中。XmlNodeList支持索引访问或迭代访问。另一个抽象类XmlCharacterData扩展了 XmlLinkedNode,为其他类提供文本处理方法。
XmlNode和XmlNodeList类组成了.NET Framework中DOM的核心,表23-4是基于XmlNode的一些类。
表 23-4
|
类 名 |
说 明 |
|
XmlLinkedNode |
返回当前节点之前或之后的节点。给XmlNode.添加NextSibling和PreviousSibling属性 |
|
XmlDocument |
表示整个文档,执行DOM Level 1 和 Level 2规范 |
|
XmlDocumentFragment |
表示文档树的一个片段 |
|
XmlAttribute |
XmlElement对象的一个属性对象 |
|
XmlEntity |
一个已分析或未分析的实体节点 |
|
XmlNotation |
包含在DTD或模式中声明的记号 |
表23-5中的类扩展了XmlCharacterData。
表 23-5
|
类 名 |
说 明 |
|
XmlCDataSection |
表示文档中CData部分的一个对象 |
|
XmlComment |
表示一个XML注释对象 |
|
XmlSignificantWhitespace |
表示带有空白的节点。只有PreserveWhiteSpace标志为true时,才能创建节点 |
|
XmlWhitespace |
表示元素内容中的空白格,只有PreserveWhiteSpace标志为true时,才能创建节点 |
|
XmlText |
元素或属性的文本内容。 |
最后,表23-6的类扩展了XmlLinkedNode。
表 23-6
|
类 名 |
说 明 |
|
XmlDeclaration |
表示声明节点 (<?xml version='1.0'…>) |
|
XmlDocumentType |
与文档类型声明相关的数据 |
|
XmlElement |
一个XML元素对象 |
|
XmlEntityReferenceNode |
表示一个实体引用节点 |
|
XmlProcessingInstruction |
包含XML处理指令 |
可以看出,.NET使其类适合于任何XML类型。因此,该工具集是非常灵活和强大的。我们不打算详细介绍每个类,而是用几个示例来说明可以完成什么任务。其层次结构如图23-5 所示。
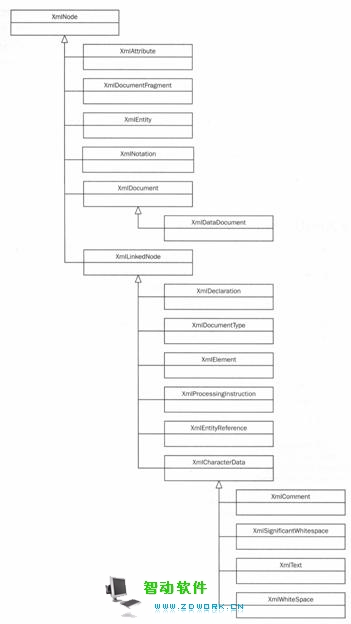
图 23-5
XmlDocument及其派生类XmlDataDocument(详见本章后面的内容)是用于在.NET中表示DOM的类。与XmlReader 和 XmlWriter不同,XmlDocument具有读写功能,并可以随机访问DOM树。XmlDocument类似于MSXML中的DOM执行方式。如果您用MSXML编过程序,就会觉得使用XmlDocument很合适。
下面介绍的示例创建一个XmlDocument对象,加载磁盘上的一个文档,再从标题元素中加载带有数据的列表框,这类似于XmlReader一节的示例,区别是本例选择要使用的节点,而不是像XmlReader示例那样浏览整个文档。
下面是该示例的代码,与XmlReader示例相比,这个示例是比较简单的(该文件在下载的DOMSample1文件夹中):
private void button1_Click(object sender, System.EventArgs e)
{
// doc is declared at the module level
// change path to match your path structure
doc.Load("..\\..\\..\\books.xml");
// get only the nodes that we want
XmlNodeList nodeLst=doc.GetElementsByTagName("title");
// iterate through the XmlNodeList
foreach(XmlNode node in nodeLst) listBox1.Items.Add(node.InnerText);
}
注意,我们在本节的示例中添加了模块级的声明:
private XmlDocument doc=new XmlDocument();
如果这就是我们需要完成的工作,使用XmlReader加载列表框就是一种非常高效的方式,原因是我们只浏览一次文档,就完成了处理。这就是XmlReader的工作方式。但如果要重新查看某个节点,最好使用XmlDocument。扩展该示例,添加另一个事件处理程序(即DOMSample2):
private void listBox1_SelectedIndexChanged(object sender, System.EventArgs e)
{
//create XPath search string
string srch="bookstore/book[title='" + listBox1.SelectedItem.ToString()
+ "']";
//look for the extra data
XmlNode foundNode = doc.SelectSingleNode(srch);
if(foundNode != null)
MessageBox.Show(foundNode.InnerText);
else
MessageBox.Show("Not found");
}
在这个示例中,与上一个示例一样,从books.xml 文档中加载了带有标题的列表框。单击列表框,会引发SelectedIndexChanged()事件,获取列表框中所选项的文本(书名),创建一个XPath 语句,把它传送给doc对象的SelectSingleNode() 方法,该方法返回title是书名的一部分的book元素(foundNode)。在消息框中显示节点的InnerText。继续单击列表框中的项目,此时文档已经加载,且一直到释放它之前,它都处于已加载状态。
下面简要介绍一下SelectSingleNode()方法,它是XmlDocument类的Xpath实现,SelectSingleNode ()和 SelectNodes()都是在XmlNode中定义的,而XmlDocument是基于XmlNode的。SelectSingleNode()返回一个XmlNode,SelectNodes()返回一个XmlNodeList。System.Xml.XPath命名空间包含许多Xpath实现。后面的一节会介绍它们。
前面的示例使用XmlTextWriter创建一个新文档。其局限性是不能把节点插入到当前文档中。而使用XmlDocument类可以做到这一点。把上一个示例中的button1_Click()事件处理程序作如下改动(在下载代码的DOMSample3中):
private void button1_Click(object sender, System.EventArgs e)
{
//change path to match your structure
doc.Load("..\\..\\..\\books.xml");
//create a new 'book' element
XmlElement newBook=doc.CreateElement("book");
//set some attributes
newBook.SetAttribute("genre","Mystery");
newBook.SetAttribute("publicationdate","2001");
newBook.SetAttribute("ISBN","123456789");
//create a new 'title' element
XmlElement newTitle=doc.CreateElement("title");
newTitle.InnerText="The Case of the Missing Cookie";
newBook.AppendChild(newTitle);
//create new author element
XmlElement newAuthor=doc.CreateElement("author");
newBook.AppendChild(newAuthor);
//create new name element
XmlElement newFTEL=doc.CreateElement("name");
newName.InnerText="C. Monster";
newAuthor.AppendChild(newName);
//create new price element
XmlElement newPrice=doc.CreateElement("price");
newPrice.InnerText="9.95";
newBook.AppendChild(newPrice);
//add to the current document
doc.DocumentElement.AppendChild(newBook);
//write out the doc to disk
XmlTextWriter tr=new XmlTextWriter("..\\..\\..\\booksEdit.xml",null);
tr.Formatting=Formatting.Indented;
doc.WriteContentTo(tr);
tr.Close();
//load listBox1 with all of the titles, including new one
XmlNodeList nodeLst=doc.GetElementsByTagName("title");
foreach(XmlNode node in nodeLst)
listBox1.Items.Add(node.InnerText);
}
在执行这段代码后,会得到与上一个示例相同的结果,但本例在列表框中添加了一本书:The Case of the Missing Cookie。单击cookie caper标题,会显示与其他标题一样的信息。中断代码,可以看出,这是一个相当简单的过程。首先,创建一个新的book元素:
XmlElement newBook = doc.CreateElement("book");
CreateElement()有3个重载方法,可以指定:
● 元素名
● 名称和命名空间URI
● 前缀、本地名和命名空间
创建了该元素后,就要添加属性了:
newBook.SetAttribute("genre","Mystery");
newBook.SetAttribute("publicationdate","2001");
newBook.SetAttribute("ISBN","123456789");
创建了属性后,就要添加书籍的其他元素了:
XmlElement newTitle = doc.CreateElement("title");
newTitle.InnerText = "The Case of the Missing Cookie";
newBook.AppendChild(newTitle);
再次创建一个新的基于XmlElement的对象(newTitle),把InnerText属性设置为新书名,把该元素添加为book元素的一个子元素。对book元素中的其他元素重复这一操作。注意把name元素添加为author元素的一个子元素。这样就可以在其他book元素中得到合适的嵌套关系。
最后把newBook元素添加到doc.DocumentElement节点上,它与其他book元素同级。现在用新元素更新现有的文档。
最后,把新XML文档写到磁盘上。在这个示例中,创建一个新XmlTextWriter,把它传送给WriteContentTo方法。WriteContentTo 和 WriteTo方法都带一个XmlTextWriter参数。WriteContentTo把当前节点及其所有的子节点都保存到XmlTextWriter,而WriteTo只保存当前节点。因为doc是一个基于XmlDocument的对象,它表示整个文档,所以应保存它。我们还使用了Save方法,它总是保存整个文档,Save有4个重载方法,其参数分别是一个包含文件名和路径的字符串、基于Stream的对象、基于TextWriter的对象和基于XmlWriter的对象。
我们还在XmlTextWriter上调用了Close()方法,刷新内部缓存,并关闭文件。
在运行这个示例时,会得到如图23-6所示的屏幕图。注意列表框底部的新项。

图 23-6
如果要从头开始创建一个文档,可以使用XmlTextWriter(见本章前面的介绍)。还可以使用XmlDocument。使用哪个比较好?如果要写入XML流的数据已经准备好,最好选择XmlTextWriter类。但是,如果需要一次建立XML文档的一小部分,在不同的地方插入节点,用XmlDocument创建文档就比较好。为此,可以把下面的代码:
doc.Load("..\\..\\..\\books.xml");
改为(这些代码在示例DOMSample4中):
//create the declaration section
XmlDeclaration newDec = doc.CreateXmlDeclaration("1.0",null,null);
doc.AppendChild(newDec);
//create the new root element
XmlElement newRoot = doc.CreateElement("newBookstore");
doc.AppendChild(newRoot);
首先创建一个新XmlDeclaration,其参数是版本(目前是"1.0")、编码(edcoding)和standalone标志。如果没有使用null,编码参数应设置为一个字符串,该字符串应是System.Text.Encoding类的一部分。null默认为UTF-8。standalone标志可以是yes、no或null,但如果是null,就不使用该属性,也不包含在文档中。
要创建的下一个元素是DocumentElement。在本例中,它称为newBookstore,这样区别就比较明显。代码的其余部分与前面的示例相同,执行的方式也相同。下面是从代码中生成的booksEdit.xml:
<?xml version="1.0"?>
<newBookstore>
<book genre="Mystery" publicationdate="2001" ISBN="123456789">
<title>The Case of the Missing Cookie</title>
<author>
<name>C. Monster</name>
</author>
<price>9.95</price>
</book>
</newBookstore>
本章没有介绍XmlDocument类的每个细节,也没有介绍在.NET中对创建DOM模型有帮助的其他类。但是,我们说明了.NET中的DOM有多么灵活和强大。在希望随机访问文档时,可以使用XmlDocument类。在希望有一个流类型的模型时,可以使用基于XmlReader的类。基于XmlDocument的XmlNode的灵活性要求的内存比较多,读取文档的性能也没有使用XmlReader好,所以应仔细考虑在这种情况下最好使用什么方法。
